

作业调度(作业调度和进程调度的主要功能)
作业调度(作业调度和进程调度的主要功能)
作业调度
分享嘉宾:陈武 虎牙 大数据架构师
编辑整理:杨哲 达州银行功能
出品平台:DataFunTalk
导读:今天为大家介绍虎牙的离线作业调度系统,以及如何通过基线调度实现成本优化。主要包括以下几大部分:
调度系统的定位及区别发展系统设计基线调度的关键实现未来发展
--
01
调度系统的定位及发展
1. 定位
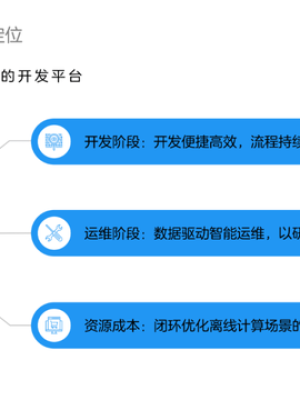
离线计算调度系统的定位,作业调度问题,从它的名字上可以看出,是在离线计算场景范围内的开发平台。
首先要解决的问题是开发阶段的便捷高效,开发人员不用关心工程、环境上的问题;其次是要解决开发过程中的管理问题,作业调度系统,比如版本控制、权限控制等。
开发完成上线之后,来到运维阶段。我们期望以工作数据驱动,实现自动运维,无需研发人员介入,实现故障自动定因或者进一步故障自愈。
通常离线计算处理的数据量都比较大,如何进行成本优化,也是我们要考虑的问题。
2. 发展历程
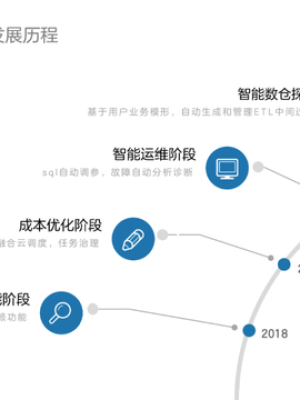
基于上述定位,虎牙的离线调度系统经历系统了如下的发展历程。
早在2018年,调度系统就已经存在了,而且运行了3年左右。这个时期的调度平台,已经解决了开发阶段的问题,实现了可视化的计算任务开发、版本控制、多人协作等功能。当时我们的任务量,每天接近10w以上,任务量也算是比较大的。
接下来2019-2020年,我们主要做的是成本侧的优化。比如基线调度梳理,多机房融合云调度,任务治理等工作。
2021年开始,我们开始在智能运维方向进行了一些探索,包括故障自动分析,甚至自动自愈等。
未来我们将在智能数仓方向上做进一步探索。
3. 收益
经过上述发展历程后,我们进程对成本进行中选了全面的评估。
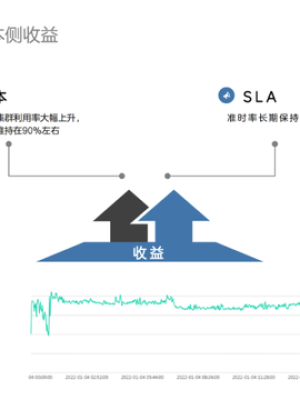
因为离线任务调度任务对于资源的需求集中在凌晨0点到9点,剩余的时间都比较空闲。经过我们调整优化后,可以看到虎牙的yarn集群利用率24小时的分布情况,在0-20点的20个小时中,整体的利用率都比较平均,时间维度上利用率可以达到90%。SLA也一直保持在90%以上。怎么理解这个利用率呢?如果整个计算任务执行完成需要1w台机器的算力占用持续9个小时,那么将同样的计算任务平均分配到20个小时只需要5000台机器的算力。
我们是如何实现这样的成本优化的呢?接下来是什么将为大家介绍我们的系统设计。
--
02
系统设计
1. 整体介绍
首先整体介绍一下虎牙调度系统。下图是调度产品的一个缩影。

调度系统强调任务流程之间的逻辑关系,致力于完成一个任务调度有向功能无环图(DAG)的配置,在数据库中会保留这样的逻辑,甚至在运行或者代码中也会嵌入这些逻辑关系,势必会造成跨流程依赖的问题。
我们的调度系统是强调对任务的分类分配,淡化任务逻辑关系的关注。通过对任务各方面信息的采集,在后台根据这些信息将任务进行算力优先级编排。
绿色框部分是一些任务插件,比如hive,SparkSql等。
下面的中选可执行平台频次,就是一个Crontab表达式,来指定任务执行的周期,作业调度计算公式。
再往下是配置是什么任务依赖,相当于DAG的流程编排,这个稍后会详细说明。
下面是重要程度,是制定任务的算力优先级,这个直接影响到整个的任务编排。
高级平台属性,包括设置任务调到哪一类接口机去跑、它的重试次数等。
最后是一些监控类的设置程序。
2. 时间依赖
下面详细介绍时间依赖的调度设计必须做。
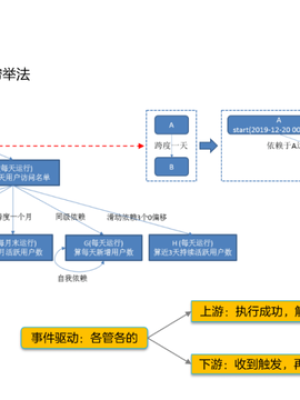
市面上对于时间周期性的任务,通常采取穷举法来实现调度,比如一个任务每3个小时执行,那么会把这个任务所有执行的两个时间点计算穷举出来(即0点、3点、6点...)。我们的做法是抽象出时间跨度的概念(类似于Oracle定时任务Job里面指定频率的概念),同样每三个小时执行表达为(0+3),即从0点开始间隔为3小时。
第二个不同是我们的任务触发是完全基于事件驱动的。上游任务只需要发出自身执行完成信号,触发下游的任务进行依赖检测。下游收到出发后,自行根据配置的依赖项去检测,是否具备执行条件状态。
比如A任务跨度为一天,间隔为15分钟,B任务的依赖是A任务全天的执行完成。当A任务的全部计划执行完成后状态,会去触发B任务,B会检测A任务当天所有任务执行完成后才会开始执行。
3. 部署架构
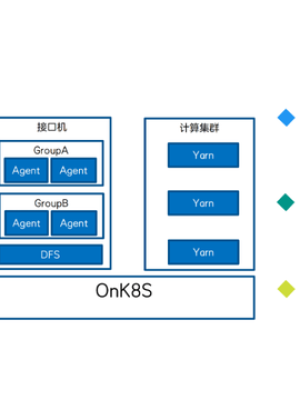
我们整个必须做任务调度流程是:首先任务调度中心去数据库中获取任务的基本信息,然后根据不同的任务类型生成任务的实例分配到不同的接口机(Agent),最后由接口机将任务实例提交到Yarn执行。
我们的接口机(Agent)是部署在分布式文件系统上的,而且是无状态的,方便伸缩。
--
03
基线调度的关键实践
前面我们已经介绍了调度平台的整体情况,接下来介绍我们如何在此基础上既保障用户的SLA,又提高Yarn的利用率。
1.作业 成本优化三板斧

SLA的定义和管理:我们要确保成本优化不能影响用户使用,用SLA指导成本优化的极限,避免过度优化。降低资源消耗在时段上的过度集中:因为离线计算多集中于0-9点,所以我们要让算力尽量平摊到各时段。降低集群选取的安全buffer容量程序:buffer容量不能过大,要在合理的范围内。
2. SLA定义
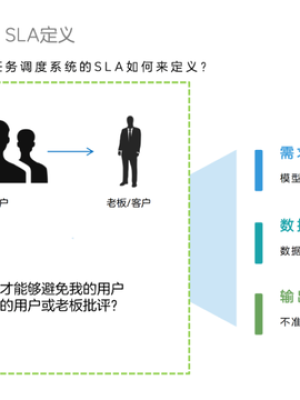
如何让用户满意,我们关键总结了三个方面改善:
需求开发周期长,通常是由数据产品开发和需求分析的同事来解决;数据效果/数据质量问题通常是业务口径或者数据治理的问题;同一个定时任务完成时间不稳定,任务准时率低,由调度工作平台来掌控,是很好的SLA指标。
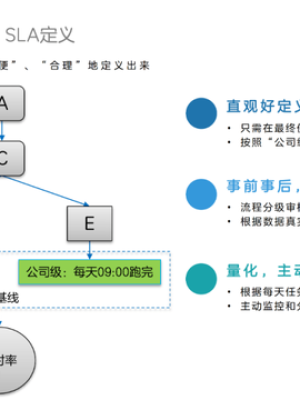
如何根据任务准时率定义SLA?如果让用户定义所有任务的准时期望是不现实的,只需要定义用户自己关心的末端任务的准时期望,剩余没有定义的我们默认为当天24点之前。
我们设计了按重要度区分的准时中选基线供用户选择,作业调度的工作,公司级、一级部门、二级部门来定义任务的优先级,同时需要部门领导进行审核,确认SLA的真实性、合理性。
完成准时基线配置后,可以很好地量化平台的SLA指标。我们会跟业务部门共同承担这个指标,因为通常故障原因有可能是任务代码的原因,也有可能是平台的原因。
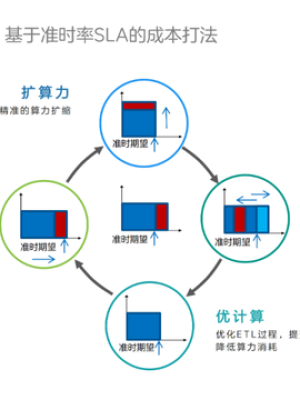
基于准时率SLA的成本打法有选取如下几种:
优计算:通过优化ETL过程,提升计算引擎效率。这种方式不在于调度平本身。调期望:找到并干掉一些用户不太合理的准时期望,调整期望时间。扩算力:增加算力投入,提升计算能力。挪任务:利用任务优先级,对任务执行时间有何进行调整,有限保障重要任务。
3. 算力平摊
哪些任务的优先级高?如何保证把算力优先给到更高优先级的任务?
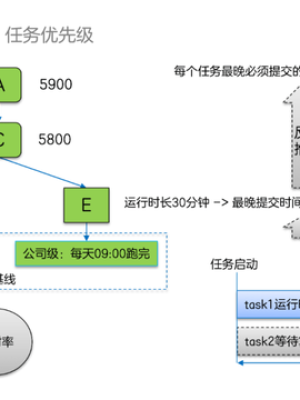
首先定义任务优先级。用户在任务链的末端节点设置了准时期望,那么上游任务的准时期望怎么工作设置?假设我们已经知道所有任务节点执行的真实时长,根据末端节点的准时期望可以递归调度倒推出所有任务的最晚开始时间。
有些任务提交到Yarn集群后进程,需要等待分配资源,有些任务直接就可以开始计算,那么任务执行的真实时长我们怎么衡量?将等待资源时间从整体任务链执行时间中减去,就得到真实时间。
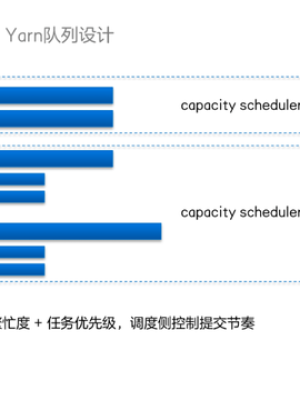
Yarn队列中的容量调度一般采用先进先出策略执行,对于周期跑数是没有问题的,但是生产环节比较复杂,会有临时跑数任务和紧急跑数任务。这种情况使用先进先出策略不太合适。比如有个很大的任务正在执行,临时出现一个小任务必须等待大任务执行完成后才能得到资源。所以我们针对临时和紧急跑数任务采用公平策略来调度。另外对于紧急跑数的任务,需要将任务挪到优先级高的队列中执行。
同时要注意调度侧配置反压策略,通过监控yarn集群的处于繁忙程度,并控制调度侧的任务提交节奏。
4. 安全buffer容量
这样配置完成后,整个yarn集群要多大才够,或者说所有任务配置完成后,需要预留多少buffer容量?如果遇到突发情况,buffer不够的情况下,如何快速提升算力?
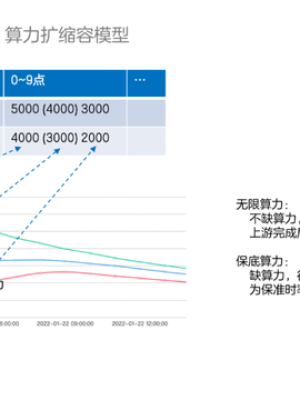
我们设计了程序一个算力扩缩容公式模型,有三条算力配置基线。无限算力是所有任务提交后立即得到资源执行;保底算力是保障任务准时率的下限;真实算力是在保底算力之上加上一定的预留算力。
对于虎牙来说,寒暑假或者大型赛事期间有何,突发大量算力缺口。我们采用云作为快速扩容手段。如何将计算任务分配到不同机房执行?我们采用了如下方法。
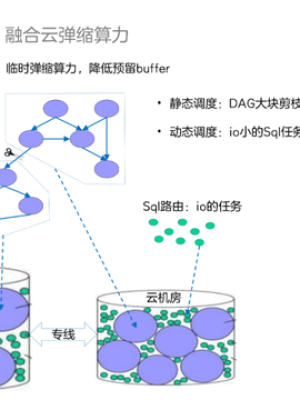
首先对日常任务的DAG运行图进行分是从块裁剪,形成多个计算成块的任务组,分发到不同的机房执行;其次将IO小的任务,动态分配到各个机房执行,填充大型任务执行的空隙。
这样我们就做到了将Yarn集群的利用率提高到90%以上。
--
04
未来发展
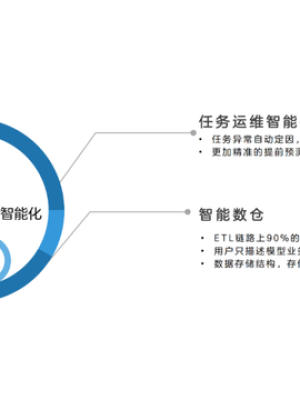
接下来我们对调度平台的规划主要是智能方向。比如说任务运维智能化、任务异常自动定因等。另外是智能数仓方向,ETL链路上90%的任务自动生成,用户只需要关注业务逻辑,不再关心计算链路和计算任务。数据的存储生命周期都由平台管理。
--
05
问答
Q:离线任务时段和实时任务时段怎么分配比较好?
A:分不同的Yarn队列,用先进先出策略处理周期性任务;公平策略应对区别临时紧急任务。
Q:DAG工作流编排可以再说算法明一下么?
A:就是在传统的工作流关键编排基础上区别附加上时间属性。
Q:是根据是什么确认数据在哪个集群来确定任务必须做提交的工作进程集群吗?
A:是。因为我们用剪辑算法切分任务DAG形成任务块,提前知道此任务块应该在哪个机房执行。对于IO小的平台是不用过多考虑的,就是动态分配。
Q:算力的预估是怎么做的,作业调度和进程调度的主要功能,是预先执行还是记录了历史算力消耗,再次提交的时候进行了重新分配?
A:是基于历史每一天任务,在不缺算力的情况下,执行的真实时长的平均数、中位数进行预估。考虑到存在一定的误差,配置算力时结合任务重要程度,进行一些扩大算力配置。
Q:调度中,任务的计算成本时怎么衡量?是否有任务和表的血缘关系?任务成本会平摊到每个表吗?
A:任务的成本没有分摊到表,是根据Yarn的队列进行分摊的,因为我们的队列是根据部门对应设置的。任务和表的血缘是有的必须做,我们会自动的解析sql,获取程序到字段级的血缘关系。
Q:多机房的计算资源是一套Yarn集群统一管理作业还是多套?
A:Yarn集群可以理解为独立的多套,通过调度平台做路由将任务分发到不同的机房执行,作业调度程序的工作有,作业调度是什么意思。
今天的分享就到这里,谢谢算法大家,作业调度。
阅读更多技术干货文章,请关注微信公众关键处于号“DataFunTalk”。
分享嘉宾:

关于我们:
DataFun:专注于大数据两个、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章700+,百万+阅读,14万+精准粉丝。
欢迎有何转载分享评论,转载请计算私信,作业调度算法。
-

- 五粮头曲(五粮头曲42度价格)
-
2023-06-16 18:19:27
-

- 活动形式有哪些(综合实践活动形式有哪些)
-
2023-06-16 18:17:20
-

- 火灾逃生的四个要点
-
2023-06-16 18:15:15
-

- 岳阳楼记是谁写的
-
2023-06-16 18:13:09
-

- 儿童山地车(儿童山地车安装教程)
-
2023-06-16 18:11:03
-

- 天皇孙笑川(天皇孙笑川经典语录)
-
2023-06-16 18:08:57
-

- 苏轼朝代(苏轼朝代及代表作)
-
2023-06-16 18:06:50
-

- 清秀的女生(清秀的女生的长相特点)
-
2023-06-16 18:04:45
-

- 北方的生肖(北方的生肖有哪几项)
-
2023-06-16 04:40:26
-

- 电话原理(手机电话原理)
-
2023-06-16 04:38:20
-

- 红警之川东军阀(抗战:红警我有无限资源)
-
2023-06-16 04:36:14
-

- 密肋板(密肋板图片)
-
2023-06-16 04:34:08
-

- 智力测试国际标准(智力测试国际标准版)
-
2023-06-16 04:32:03
-
- 紫光展锐是国企吗
-
2023-06-16 04:29:57
-

- 古代帅哥(古代帅哥的称呼)
-
2023-06-16 04:27:51
-

- 瞎猫碰上死耗子(瞎猫碰上死耗子是贬义词吗)
-
2023-06-16 04:25:46
-
- 水浒传人物绰号大全(水浒传108位好汉的名字和绰号)
-
2023-06-16 04:23:40
-

- 西藏探险(去西藏探险)
-
2023-06-16 04:21:34
-

- 自热小火锅的发热包怎么用
-
2023-06-15 21:07:31
-

- 紫砂杯喝水的好处是什么
-
2023-06-15 21:05:25
 有人见过范冰冰本人吗(见过范冰冰本人是一种什么体验?)
有人见过范冰冰本人吗(见过范冰冰本人是一种什么体验?) 男生拥抱的时候摸你头发
男生拥抱的时候摸你头发