

谷歌ai聊天机器人(不再鹦鹉学舌26亿参数量)
谷歌ai聊天机器人(不再鹦鹉学舌26亿参数量)
来源:机器之心
开放领域聊天机器人是人工智能研究的一个重要领域。近日谷歌一篇博客介绍了团队在该领域的最新研究进展——Meena 机器人。
现在的对话智能体(即聊天机器人)都是非常专业化的,如果用户不偏离场景太远的话,这些机器人的表现还是很不错的。但是,要想让聊天机器人能够完成更广泛话题下的对话任务,发展开放领域聊天机器人就显得很重要了。
开放领域聊天机器人不会仅限于在某个特定领域,而是能够和用户聊近乎所有的话题。这一研究不仅具有学术价值,还可以激发很多有趣的应用,如更深层次的人机交互、提升外语训练的效果,或用于制作交互式电影和游戏角色。
但是,现在的开放领域聊天机器人有一个严重的缺陷——它们产生的对话内容往往没什么意义。要么它们的对话和当前的内容没什么连贯性,或者对现实世界没有常识和基本知识。此外,它们对于当前的语境往往给不出特定的回复。例如,「我不知道」确实是一个可以回答任何问题的答复,但是不够详细。现在的聊天机器人产生这种回复的频率比人类要高很多,因为这种回复可以覆盖很多可能的用户输入。
为了解决这些问题,谷歌的研究者提出了一个新的聊天机器人,名为 Meena。这是一个有着 26 亿参数的端到端神经对话模型,也就是 GPT-2 模型最大版本(15 亿参数)的 1.7 倍。通过实验可以看到,Meena 比现有的 SOTA 聊天机器人能够更好地完成对话,对话内容显得更为具体、清楚。
在测评中,谷歌采用了他们新提出的人类评价指标,名为「Sensibleness and Specificity Average (SSA)」。这个指标能够捕捉基本但对于人类对话重要的属性。值得注意的是,研究者同时还发现,困惑度——一个很容易在各种神经对话模型中实现的计算指标,和 SSA 有着高度的相关性。
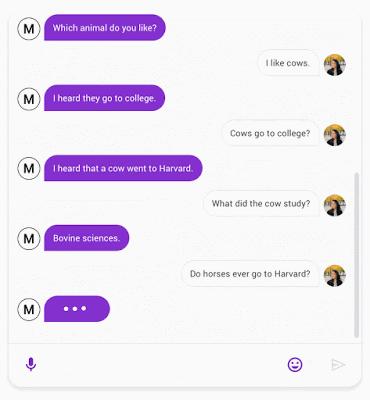
Meena(左)和人类(右)之间的对话。
Meena 机器人
Meena 是一个端到端的神经对话模型,可以学习如何对给定的对话上下文做出响应。训练 Meena 的目标是最大程度地减少困惑度,以及预测下一个标记(在这种情况下为对话中的下一个单词)的不确定性。
其核心为 Evolved Transformer seq2seq 架构,也就是通过进化神经架构搜索发现的一种 Transformer 体系结构,可以改善困惑度。
Meena 由一个 Evolved Transformer 编码器和 13 个 Evolved Transformer 解码器组成,如下图所示。编码器用于处理对话语境,帮助 Meena 理解对话中已经说过的内容。解码器则利用这些信息生成实际的回复。通过超参数调整后,研究者发现性能更强的解码器是实现高质量对话的关键。
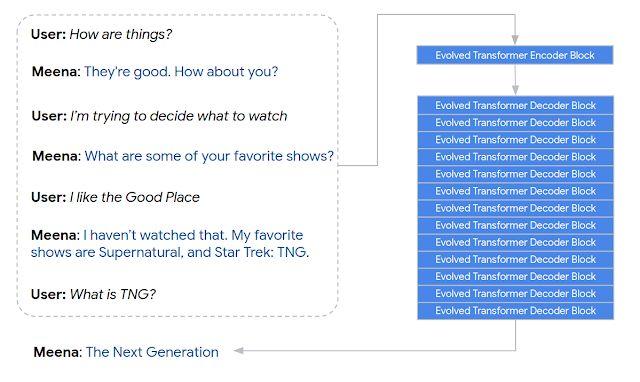
Meena 根据七轮对话的语境生成回复。
用于训练的对话语料以树状脉络形式组织起来,每个回复可以被认为是一轮对话。研究者将每轮对话抽取作为训练样本,而该轮之前的 7 轮对话作为语境信息,构成一组数据。选择 7 轮对话作为语境是因为它既能够获得足够长的语境信息,也还能够让模型在内存限制下进行训练。毕竟文本越长,内存占用就越大。
据博客介绍,Meena 在 341GB 的文本上进行了训练,这些文本是从公共领域社交媒体对话上过滤得到的,和 GPT-2 相比,数据量是后者的 8.5 倍。
人类评价指标 SSA
现有聊天机器人的人类评价指标有些复杂,而且在评价者间也很难形成标准一致的评价。这使得研究者设计了一种新的人类评价指标,名为「Sensibleness and Specificity Average (SSA)」。
为了计算 SSA,研究者使用众包方式测试了 Meena、Mitsuku、Cleverbot、小冰和 DialoGPT 等聊天机器人。为了保证评价的连贯性,每个对话都以「Hi」开始。在评价中,人类评价者需要回答两个问题:「对话讲得通吗?」以及「对话够详细具体吗?」评价者使用常识评价聊天机器人的回复。
在评价中,只要有令人困惑、不合逻辑、跑题或者事实性错误的回复,评价者就可以打「对话讲不通」。如果对话讲得通,评价者就需要评价对话是否具体详细。例如,人类对话者说「我喜欢打网球。」,而聊天机器人仅仅回复「这很好。」就可以判断对话是不够具体详细的,因为没有针对语境进行回复。
对于每个聊天机器人,研究者收集了 1600 到 2400 轮对话。每个模型的回复都被人类评价者打上评价结果的标签(对话是否讲得通和对话是否具体详细)。最后的 SSA 分数是两者的均值。如下结果说明,Meena 相比于现有的 SOTA 聊天机器人有着更高的 SSA 分数,接近了人类的表现。
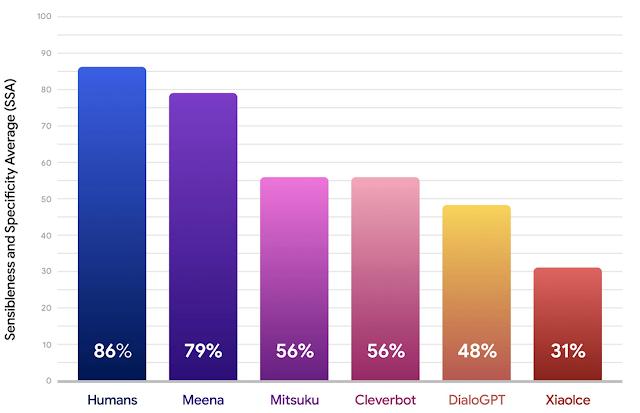
Meena 和其他聊天机器人的性能对比。
困惑度指标
但是,由于人类评价存在的问题,很多研究者都希望找到一个能够自动计算的评价指标。这个指标需要能够和人类评价精确对应。研究者在研究中发现,困惑度(perplexity),一个在 seq2seq 模型中常见的指标,和 SSA 有着强相关性。
困惑度用于评价一个语言模型的不确定性,低困惑度说明模型在生成下一个 token(如字、词等)时有着更高的信心。困惑度表示的是模型在选择生成下一个 token 的过程中的候选数量。
在研究中,研究中采用了 8 个不同的模型版本,分别有着超参数和架构上的区别,如层数、注意力 head 数量、训练步数,使用的是 Evolved Transformer 还是一般的 Transformer,使用 hard label 进行旋律还是使用蒸馏的方法进行训练等。从下图来看,越低的困惑度模型有着更高的 SSA 分数,而两者的相关系数很强(R^2 = 0.93)。
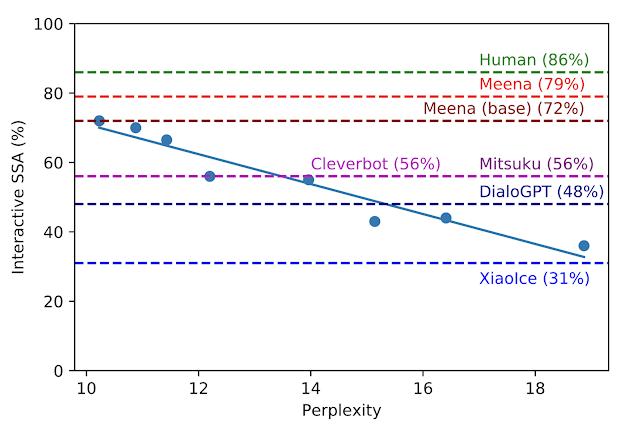
交互式 SSA vs. 困惑度。每个蓝点都是都是 Meena 模型的不同版本。这里绘制出了回归曲线,表明 SSA 与困惑度之间存在很强的相关性。虚线则表示了人,其他机器人,Meena(base),端到端的训练模型以及具有过滤机制和调整解码的 Meena。
最好的端到端 Meena 训练模型,被称之为 Meena(base),实现了 10.2 的困惑度(越小越好)转化为 72% 的 SSA 得分。与其他获得 SSA 分数相比,72% 的 SSA 分数与普通人获得的 86% 的 SSA 分数相差不远。Meena 的完整版具有过滤机制和调整解码,会进一步将 SSA 分数提高到 79%。
未来的研究与挑战
按照之前的描述,研究者将继续通过改进算法、架构、数据和计算量去降低神经会话模型的困惑度。
虽然研究者再这项工作中只专注于敏感性和独特性,而其他属性如个性和真实性等依旧值得在后续的工作中加以考虑。此外,解决模型中的安全性和偏差也是一个关键的重点领域,鉴于当下面临的挑战是与此相关的,就目前而言团队不会发布研究演示。但是,研究者正在评估将模型检查点具体化所带来的风险及益处,并且有可能会选择在未来几个月内使其可用,用来帮助推进该领域的研究工作。
参考链接:
https://c.quk.cc/2/c12/ccwncawn5hs src="https://c.quk.cc/2/c12/nu2l3ll2s5k.jpg" alt="谷歌ai聊天机器人(不再鹦鹉学舌26亿参数量)(6)" >
,
-

- 嫌疑人x的献身日本的深度解析(我是这样解读嫌疑人x的献身的)
-
2023-11-07 03:22:38
-

- 刘伯勋演员怎么死的(41岁男演员刘伯勋突发心梗离世)
-
2023-11-07 03:20:32
-

- 17岁少年跳桥事件后续(17岁男孩跳桥自杀)
-
2023-11-07 03:18:26
-

- 娄艺潇演过的电视剧接吻(俩月被曝3段恋情)
-
2023-11-07 03:16:20
-

- 经常失眠怎么办男生(经常失眠怎么办?)
-
2023-11-06 19:41:15
-

- 江西结婚风俗及流程男方(江西结婚风俗及流程)
-
2023-11-06 19:39:10
-
- 个性字转换器在线转换器(个性文字转换器)
-
2023-11-06 19:37:05
-

- 二手菲亚特500值得购买吗?二手菲亚特500发动机
-
2023-11-06 19:35:00
-

- 小米电信版能用移动卡吗知乎?小米电信卡可以办宽带不?
-
2023-11-06 19:32:55
-

- 中国人寿分红型保险可靠吗(中国人寿分红型保险怎么查询分红)
-
2023-11-06 19:30:50
-

- 长春技术学校哪个学校最好(长春技术学校有哪些专业)
-
2023-11-06 19:28:46
-

- 张家界玻璃桥在哪里(张家界玻璃桥有多长)
-
2023-11-06 19:26:41
-

- 随身仙家洞府顶点小说 随身携带仙家洞府
-
2023-11-06 19:24:36
-

- 氧化钙生产厂家联系方式(淄博氢氧化钙生产厂家)
-
2023-11-06 19:22:31
-

- 李玉刚跳河事件是真的吗(曾经要饭乞讨的李玉刚现状如何)
-
2023-11-06 06:40:48
-

- 失望型分手怎么挽回(如何挽回失望型分手)
-
2023-11-06 06:38:42
-

- 沃尔沃XC60常规保养项目价格总结(沃尔沃xc60售后保养贵不贵)
-
2023-11-06 06:36:35
-

- 关于牧童的古诗十首(牧童归去横牛背)
-
2023-11-06 06:34:30
-

- 描写春天景色的作文(描绘春天的作文)
-
2023-11-06 06:32:24
-

- 日本代购必买30款(代购带火的产品)
-
2023-11-06 06:30:18
 云南本地人为什么不会被骗到缅甸(看看真实的缅北)
云南本地人为什么不会被骗到缅甸(看看真实的缅北) 中国一线男装10大品牌(盘点国内十大知名男装品牌排行榜)
中国一线男装10大品牌(盘点国内十大知名男装品牌排行榜)