

apachedoris架构原理及特性(基于Doris的知乎)
apachedoris架构原理及特性(基于Doris的知乎)
导读:本次分享题目为基于Doris的知乎DMP系统架构与实践,由知乎用户理解&数据赋能研发Leader 侯容老师带来经验分享,主要围绕四个方面展开介绍:
背景:知乎DMP的业务背景、流程、特征及功能介绍架构与实现:知乎DMP的架构设计和实现难点及解决方案:知乎DMP平台建设的难点和解决方案未来展望:知乎DMP平台下一步迭代方向

01
背景
DMP本身是个老生常谈的业务领域,在广告系统出现的时候就有了类似DMP平台的系统。业界做得比较好的有腾讯广点通、阿里达摩盘。
知乎搭建DMP的原因可简单概括为:知乎存在大量站内运营的业务需要,搭建DMP平台需要支持同知乎内部系统的对接,搭建DMP存在一定量的知乎定制化需求,需要适配知乎的内部运营流程。
1. DMP业务背景
首先,抛出问题:知乎业务中具体存在哪些问题需要解决?为什么要建立DMP平台来解决这些问题?
下面围绕业务模式、业务场景、业务需求等三个主要方面,来具体说明建设DMP平台的必要性和功能定位。
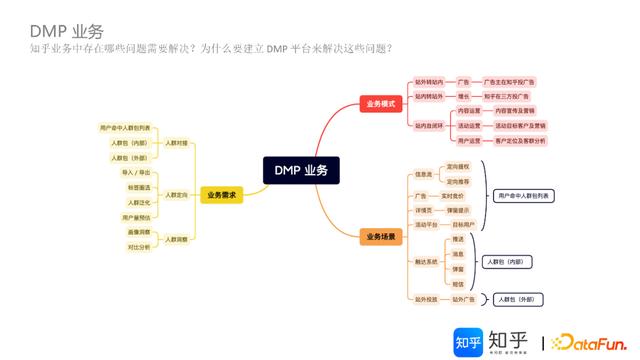
(1)业务模式
如何找出核心客户,围绕某个客户应该如何运营、如何适配营销操作、以及广告投放,如何进行人和业务的匹配,都需要完成对人的定向、对人的画像洞察,以及对人的理解和运营操作,这些都是DMP的主要业务定位。
知乎DMP主要包括三种业务模式:
站外转站内,典型的场景是,在广告侧有广告主在知乎平台投放广告,触发站外人群,如何通过一个Mapping将站外人群承接到站内,且在站内的各个系统上能够承接这些用户包。站内转站外,典型的场景是,增长投放方面,如何在知乎平台找到一个定向价值用户群,再针对这些用户包到三方平台进行广告投放。站内自闭环,主要是知乎内部运营,包括内容运营、用户运营、活动运营等,一方面增加内容宣传和营销;一方面完成客户的定位及客群分析,解决一些客户问题;策划一些活动,促成客户价值提升和针对营销效果达成。
(2)业务场景
针对上述三种业务模式,知乎DMP适配了多种业务场景:
信息流,比如推荐场景,有一些定向推荐、定向提权等诉求,把某些内容推给谁,某些内容针对特定客户进行定向提权,去重新打分等。广告,比如实时竞价,基于一个客户身上挂的广告特征,进行实时竞价,排序筛选最合适的广告推送。详情页,比如弹窗提示,当用户进入详情页,根据触发的规则条件情况,进行相关的访问引导。活动平台,比如目标用户,对该活动是否可见?哪些活动可见?等进行管理适配。触达系统,比如推送、消息、弹窗、短信等,针对具体的客群进行Push、站内信等触达。站外投放,比如站外广告,面向特定的人群,进行站外广告触达。
(3)业务需求
基于三种业务模式、六种业务场景的拆解分析,提炼出人群管理的功能需求主要包括:
人群对接,主要是对接系统,无论是站外系统还是站内系统,基础需求是用户命中了哪些人群包——以广告系统为例,人群包的ID可以Mapping为一则广告,即一个用户身上可以挂哪些广告;其次是人群包(内部),把人群推荐给谁,或者把哪些内容推送给该人群;最后是人群包(外部),主要围绕外部广告投放场景,提供人群包服务。后两种主要在内部统一ID和外部多平台ID等管理存在差异。人群定向,主要包括导入、导出、标签圈选、人群泛化、人群用户量预估等基础功能。人群洞察,包括人群包内部画像洞察、不同人群包之间的差异对比分析等。
2. DMP业务流程
基于知乎DMP业务模式提炼、业务场景刻画、业务需求澄清等背景梳理,结合站内系统、站外系统交互协同,形成了一套业务流程。
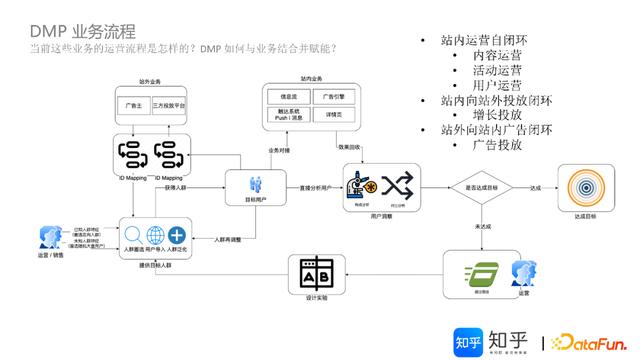
概括为四大核心功能模块:
人群定向模块,包括人群圈选、人群泛化、用户导入等;目标用户ID-Mapping模块,包括站外Mapping、站内Mapping等对接适配;用户洞察(效果评估)模块,包括构成分析、对比分析等;ABTest(活动优化)模块,包括策略设置、实验组织等。
围绕站内运营自闭环、站内向站外投放闭环、站外向站内广告闭环等人群运营,可以灵活适配活动落地。
3.DMP画像特征
在人群定向模块,存在大量的人群标签筛选、组合标签筛选的应用要求,对DMP平台的画像特征库提出很高的要求。
知乎DMP按照三层结构进行画像特征分类设计:
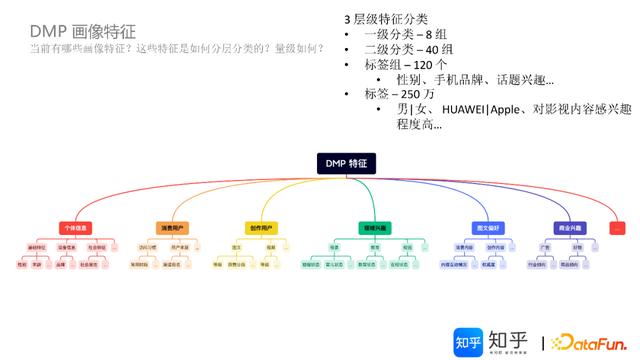
第一层分类:按主题分组,目前主要包括个体信息、消费特征、创作、兴趣、图文等8组。
第二层分类:按属性分组,比如个体信息主题包括基础特征、设备属性、社会属性等,知乎DMP目前有40组属性特征分组。
第三层分类:按标签类分组,比如性别类、手机品牌类、话题类等,目前有120类标签。
基于以上三层特征设计,知乎DMP画像特征库已有标签(标签值)超过250万。
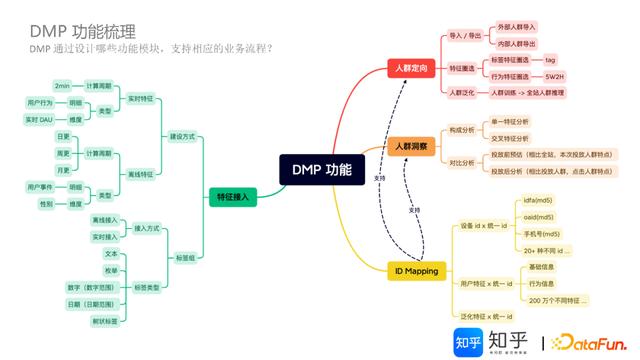
4.DMP功能梳理
按照业务功能和特征管理两大能力进行说明:
业务功能主要服务于运营、营销、站内应用系统等,包括人群定向、人群洞察、ID-Mapping等。特征管理的核心是特征应用接入,在大规模标签特征基础上,结合用户群体关联、以及实时特征要求,这部分技术支撑依赖比较重。
详细的功能分布参见下图:
--
02
架构与实现
一套好的架构设计,能够有效降低业务功能实现的复杂度;能够支撑业务功能动态扩展与迭代;对于有外部交互的系统,能够保障系统的兼容性和开放性;能够保持系统运维的便捷性。
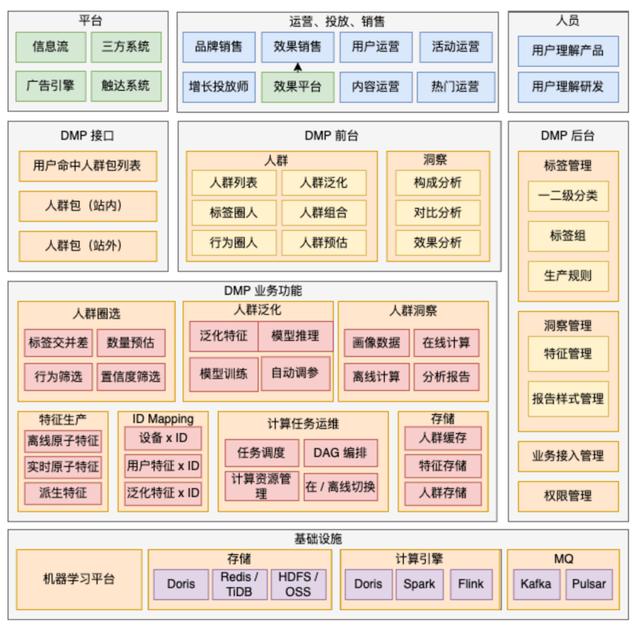
1.DMP平台架构
知乎DMP平台的整体架构,不同模块进行差异化设计:
对外模块:
lDMP接口:高稳定性、高并发高吞吐。
lDMP前台:操作简单,低运营使用成本。
lDMP后台:日常开发工作配置化,降低开发成本。
业务模块:
人群圈选:可扩展。新增特征0成本,新增规则低成本。人群洞察:可扩展。新增特征0成本,新增洞察方式低成本。人群泛化:可扩展。新增泛化方式低成本。特征生产:扩展成本低。原子特征低成本生产,派生特征通过后台可配置。ID-Mapping:屏蔽ID打通逻辑。计算任务运维:屏蔽机器资源和任务依赖的逻辑。存储:可扩展可持续,不因业务成长而导致成本大幅增加。
架构分布详情,如下图示:
2.DMP平台功能盘点
按照业务向、基础向两部分进行特征功能介绍。
(1)业务向功能
核心功能为人群定向、人群洞察两部分,分别支撑业务应用侧和价值运营侧服务。
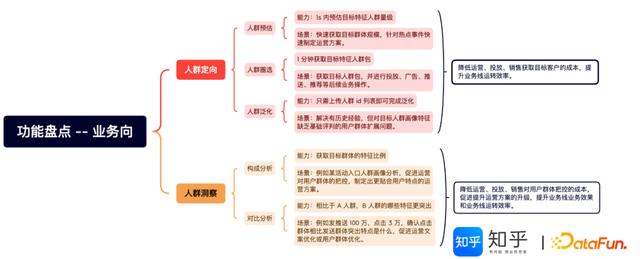
知乎DMP业务向功能上线运营情况介绍:
支持了5.2万人群定向;支持340次人群洞察;支持59次人群泛化。
(2)基础向功能
主要包括特征建设、ID-Mapping能力、计算任务运维等三部分工作,形成三组专业小组分工协同。
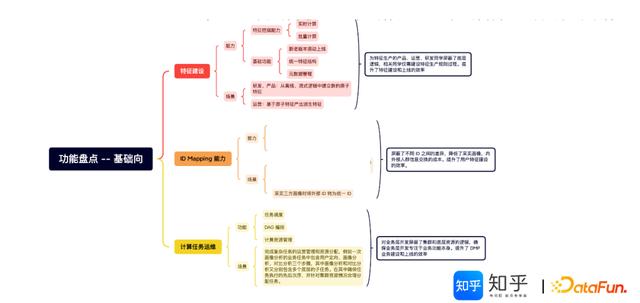
知乎DMP基础向功能运营情况介绍:
每日2.0 TB共5日11TB(离线、实时)特征——Doris。120个离线生产任务和5个实时生产任务。每日6100次人群评估,300个人群圈选,1-2个人群洞察,1个人群泛化任务。
3.DMP特征数据链路及存储
数据导入/存储、快速查询/读取,是DMP平台关键的数据技术环节。
DMP的批量、流式特征如何建设并落地到相应的存储?
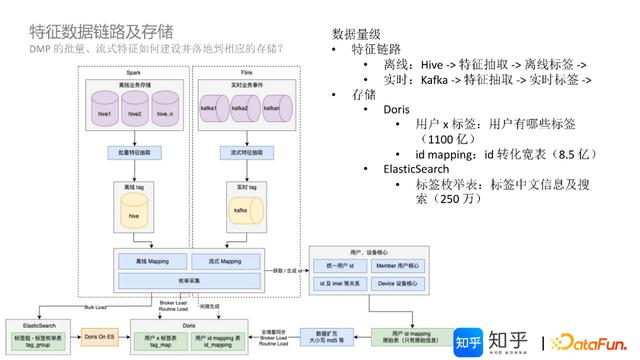
(1)离线标签链路(Spark批处理计算过程)
基于Hive中的各类业务数据,进行SQL批量计算,生成tag表(落地Hive表);基于tag表再进行Mapping计算——主要通过用户/设备核心完成的统一ID计算,生成连续的自动ID,同时完成ID、Imei、IDsa等统一转换和唯一绑定;如果是一个新用户,则生成一个新ID,如果是一个老用户,则直接获取已有ID,这个过程维护了一张ID-Mapping表,继而附加各类MD5加密等处理过程,形成用户唯一ID、各类ID映射关系表。知乎DMP中的ID-Mapping表已存储约8.5亿的ID转化宽表数据。
(2)实时标签链路(Flink实时计算处理过程)
基于Kafka中的各类业务数据,进行流式特征计算,生成实时tag表(Kafka数据);基于tag表进行流式Mapping计算,通过用户/设备核心完成统一ID计算(过程同上)。
(3)枚举采集
即250万标签的应用服务能力。
知乎DMP平台现有的125个标签类分组,分别由120个离线业务存储过程和5个实时业务事件过程计算完成,已经生成了各类原子标签。
ES标签搜索存储:在面向标签筛选应用环节,大规模标签录入操作成本太高,所有选择使用Bulk Load自动写入ES,生成标签枚举表tag_group表(存储标签中文信息及搜索,约250万记录),生成连续自增ID;
Doris中核心存储:根据ES中的连续自增ID,可以映射到Doris中用户标签表tag_map表(倒排表,用户和标签组合表,约有1100亿数据),Doris中还存在第三张表即用户行为表,是基于实时数仓够贱的,这里不做扩展介绍。
基于这三张表,给客户洞察、人群定向提供了相应的数据支撑基础。
4.人群定向流程
基于上个环节生成的ES-标签枚举表、Doris-用户标签表、Doris-ID转换映射表,进行人群定向流程解读。
场景一:通过购物车圈选人群标签,生成人群包,进行人群预估、继而完成人群圈选,最后写入Redis的过程。
第一步:标签搜索(相关标签、标签组合等设置,购物车生成)
第二步:人群预估(潜在人群包的动态评估,根据标签组合联动调整购物车配置,完成目标事件的人群匹配)
第三步:生成人群包,关联原数据、ID-Mapping 关联转换(站外);将人群包ID和人群ID写入Redis,支持高并发查询使用。若非高并发场景,可以写入离线存储机制使用。
场景二:种子人群泛化场景,依托AI平台完成模型训练和人群推理泛化,通过置信度去选择,打上人群标签和人群包,最后写会Doris的过程。
该场景包括历史效果人群泛化、圈选人群的特征泛化等。
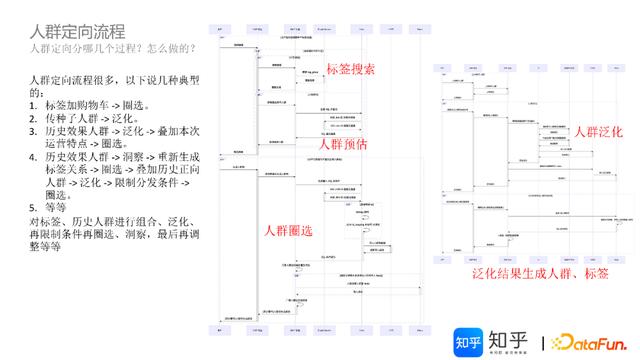
日常业务运营过程中,对标签、历史人群进行组合、泛化,再限制条件进行圈选、洞察,最后再调整等灵活组合、交叉应用模式。
--
03
难点及解决方案
本部分主要围绕人群定向方面做进行总结分享。
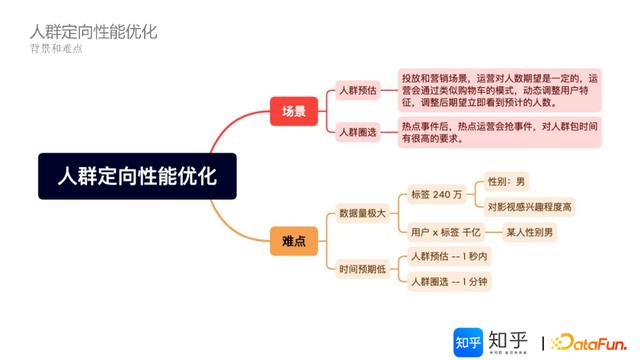
1.人群定向性能优化的痛点
知乎DMP平台关键应用模块包括人群定向和客户洞察,都依赖基础的画像特征。基于当前250万的标签特征数据基础,如何解决以下两个场景痛点:
人群定向方面关注痛点问题一:人群预估(秒级响应)——针对投放和营销场景,对人群数量期望是一定的,通过类似购物车的模式,动态调整用户特征,如何能保障快速看到预计匹配的人数?
人群定向方面关注痛点问题二:人群圈选(分钟级响应)——热点运营,当热点事件发生后,快速进行人群包圈选抢事件,对人群包时间有很高要求。
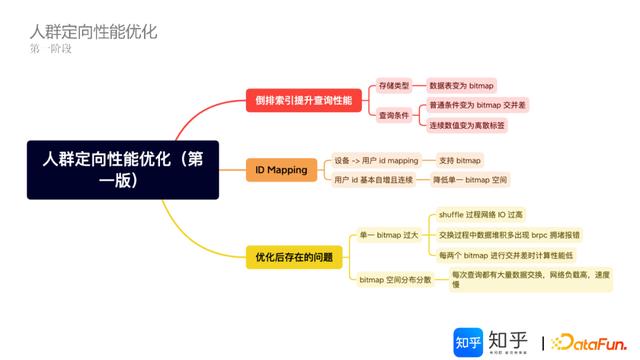
2.人群定向性能优化的思路(第一版)
解决上述性能问题的主要思路:
①倒排索引,将数据表变为bitmap。
②查询条件的与或非转变为bitmap的交并差。
③附带完成连续数值转变为离散标签,即发挥离散计算的性能优势,又提高了业务场景应用适配性。
倒排序索引,示例如下图(左)所示:
ID-Mapping适配,基于倒排序索引优化结果,在导入的过程中,完成ID-Mapping的生成(支持bitmap),实现用户ID的连续自增。如下图(右)所示:
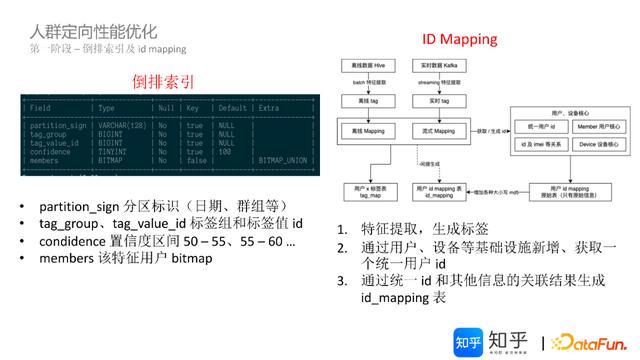
结合倒排序索引存储方式优化调整,查询逻辑变化示例如下:

经过上述优化,仍存在单一bitmap过大的问题,导致shuffle过程网络IO过大,交换过程中数据堆积Doris出现brpc传输拥堵报错,上百兆的bitmap间进行交并差计算性能低等情况;以及bitmap空间分布分散,导致每次查询都会有大量的数据交换,网络负载高,速度慢等特点。
3.人群定向性能优化的思路(第二版)
基于人群预估分钟级、人群圈选10分钟级的优化结果,再优化的核心思路是分而治之。
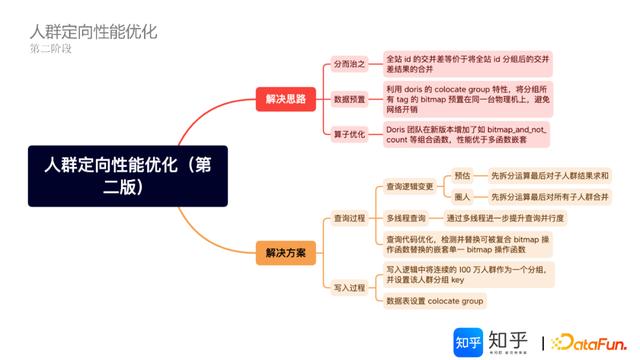
第二版优化的解决思路:基于全站ID的交并差等价于将全站ID分组后的交并差结果的合并,故分而治之思路可行;考虑利用Doris的colocate group特性,将分组所有tag的bitmap阈值在同一台物理机上,避免网络开销;同时,升级Doris新版本,利用bitmap_and_not_count等组合函数,性能优于多函数嵌套等特性。
适配第二版优化的解决方案:查询过程调整,变更预估和圈人的查询逻辑实现;发挥多线程查询计算能力;查询代码嵌套条件优化;写入过程调整,进行百万人群写入分组,设置分组key;数据表设置colocate group。
分而治之方案的具体优化逻辑,如下图所示:
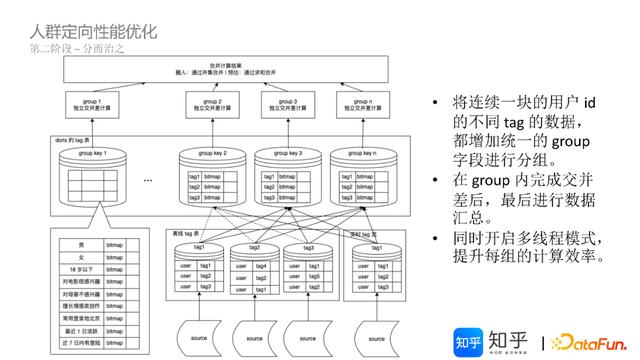
优化前后的bitmap逻辑计算复杂度对比如下图所示:
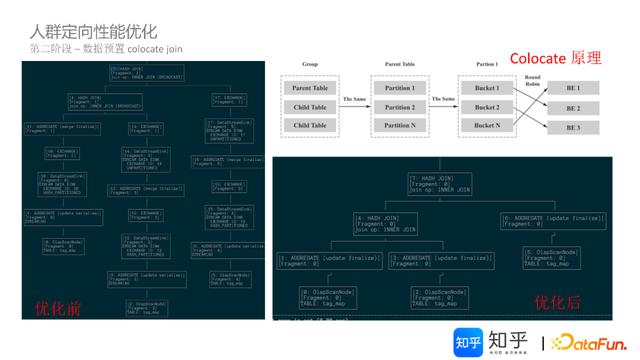
通过上述两版本优化,实现人群定向秒级响应,人群圈选分钟级响应效果。知乎DMP平台达到运营投产目标。
--
04
知乎DMP平台下一步迭代方向
1.业务运营优化
从DMP平台的多核心模块整体运营协同考虑,将目前松耦合的目标结果管理模块,同平台进行强绑定;将依赖流程绑定的A/B实验能力,与平台进行逻辑绑定。
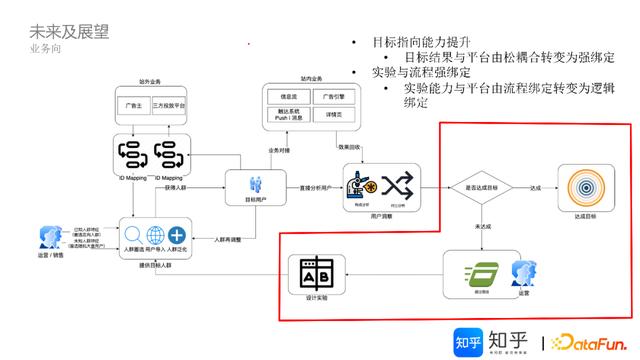
2.技术迭代优化
技术层面,主要结合平台日常运营圈选操作特点分析,实现以下两方面的提升:
查询效率提升:自动探查SQL复杂查询条件,预先合并成一个派生特征的bitmap,预测和圈选时对复杂条件SQL重写为派生特征。
导入效率提升:将每天2TB的数据导入,每15天大约会存11TB的数据,导入过程中加速策略——结合业界的Spark写OLTP引擎,考虑能否通过Spark直接写Doris Tablet文件,并挂载到FE。

今天的分享就到这里,谢谢大家。
分享嘉宾:侯容 知乎
编辑整理:李挺 上海琢学
出品平台:DataFunTalk
01/分享嘉宾

侯容|知乎 用户理解&数据赋能研发 Leader
毕业于北京化工大学,2018 年初入职知乎,在社区业务线完成多方向的业务流程建设和架构的搭建,2021 年开始负责知乎用户理解&数据赋能方向的研发团队管理,主要涵盖用户理解和实时数据的工程和业务研发。2021 年在知乎带领团队完成了实时数据系统从基建到业务层从 0 到 1 的建设及重写升级用户理解应用,形成「数据来源于业务,数据赋能于业务」的闭环,建设了相应的基建,提升了用户理解和实时数据的业务迭代效率,最终赋能业务拿到了不错的业务效果。
02/关于我们
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100 线下和100 线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章800 ,百万 阅读,14万 精准粉丝。
,
-

- 全脸整容恢复过程(越整越自然的脸)
-
2023-08-18 15:49:32
-

- 马可波罗游记云南(马可波罗花世界里穿越约起)
-
2023-08-18 15:47:09
-

- 四分钟回顾抗战史(专题不能遗忘的14年抗日征程)
-
2023-08-18 15:44:46
-

- 19岁的宋慧乔美貌惊人(撞脸宋慧乔22岁登福布斯)
-
2023-08-18 15:42:23
-

- 著名标牌设计(全球25个标识标牌)
-
2023-08-18 15:40:01
-

- 郭小川最著名的长篇叙事诗(诗词第3册第7课郭小川甘蔗林)
-
2023-08-18 15:37:38
-
- 苹果笔记本电脑(平板电脑论坛)
-
2023-08-18 15:35:15
-

- 苏打水和苏打气泡水有什么区别(横评告诉你17款苏打水)
-
2023-08-18 15:32:52
-

- 三宅一生特点(关于三宅一生的30个记忆点)
-
2023-08-18 15:30:29
-

- 董璇离婚风格大变(董璇自曝离婚后全是弟弟在追她)
-
2023-08-18 15:28:06
-

- 南澳十大必去景点(南澳这些景点太美了)
-
2023-08-18 15:25:43
-

- 使用ps做印章(PS教程利用PS制作公章)
-
2023-08-18 15:23:20
-

- 重阳节的习俗来历(重阳节的来历和风俗)
-
2023-08-18 15:20:57
-

- 各年地震情况汇总(512地震十年记忆)
-
2023-08-18 15:18:34
-

- 35岁负债抛家弃子下海经商 她负债200万走投无路时
-
2023-08-18 15:16:12
-

- 最详细云顶之弈阵容教程(云顶之弈新手向基础攻略)
-
2023-08-18 15:13:49
-

- 句号的妻子郭雅丹(句号再婚娶小11岁郭雅丹)
-
2023-08-18 15:11:26
-

- 28种木质手串识别喜欢木头的必看(42种常见的木串图鉴)
-
2023-08-18 15:09:03
-

- saas产品运营方案(心中无运营产品皆枉然)
-
2023-08-18 15:06:40
-

- 12星座适合的香水(与12星座气质相符的香水气味)
-
2023-08-18 15:04:17
 云南本地人为什么不会被骗到缅甸(看看真实的缅北)
云南本地人为什么不会被骗到缅甸(看看真实的缅北) 有人见过范冰冰本人吗(见过范冰冰本人是一种什么体验?)
有人见过范冰冰本人吗(见过范冰冰本人是一种什么体验?)